Object Detection

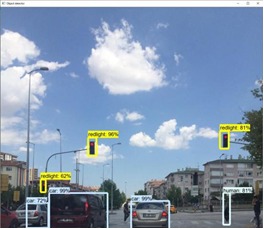



Realtime App Footage
CNN (Convolutional Neural Network)
It is one of the deep learning networks developed for images (pictures and videos, etc.) and has become quite widespread in the world. Significant developments have been achieved since 2010. In the Convolution Layer layer, the filter, which is on the top of the image, is used. This filter hovers over the image and makes calculations with the pixels of its location, depending on the type of filter, and turns each point in the relevant pixel into pixels in the new image. The last reached matrix is called the feature map. A large number of filters are used in the CNN structure. Finally, the reached Feature Map is shaped depending on the feature status in the filter.
Faster - RCNN
R-CNN (Region Based Convolutional Neural Network) and Fast R-CNN are previous models developed respectively. First of all, CNN is applied to the image, which is in Fast R-CNN, and as a result, the feature map is revealed. At the next stage, the change based on Fast R-CNN begins. Region proposals are made with the selective search method. A separate region recommendation network is created and the import is done. In the remaining stages, it is similar to Fast R-CNN. By using Faster R-CNN, the approximate forecast time is reduced to 0.3 seconds due to the time saved from the region recommendation.
YOLO (You Only Look Once)
YOLO is an algorithm that uses CNN networks to detect objects. YOLO stands for "You Only Look Once". The main reason for choosing this name is because this algorithm is fast enough to detect objects in one stage. Since the YOLO algorithm started working, it detects the objects in the images/videos and the coordinates of these objects at the same time. The difference between video and image processing: Pictures are a single frame. Video consists of many frames. While the structure of the algorithm works for a single frame in pictures, the logic in video is that it works over and over again for the frames. YOLO first divides the incoming image into regions. it then draws the box structures (bounding boxes) surrounding the objects in each region. This means that it calculates the probability of finding the object in each region. It calculates a confidence score for each bounding box it draws. This calculated score shows how likely it is that the object is the predicted object.
Transfer Learning
Because of the large amount of data required, training a neural network is different from training other machine learning models. Actually, if you want to train a CNN, you need to have a lot of data and powerful hardware. It is difficult to collect sufficient data under normal circumstances. At this stage, the pre-trained CNN network called "Transfer Learning" in the literature comes into play. In this way, a personalized network can be created by changing the output layer of CNN classifier models such as Alexnet, VGG and Resnet trained on large-scale datasets such as ImageNet and Coco, saving time and high-performance hardware. This method can train the network with less data with higher accuracy. The millions of weights and bias coefficients in the trained CNN network are calculated.